Testez l'IA sur VOTRE site web en 60 secondes
Voyez comment notre IA analyse instantanément votre site web et crée un chatbot personnalisé - sans inscription. Entrez simplement votre URL et regardez-la fonctionner !
Prêt en 60 secondes
Aucun codage requis
100% sécurisé
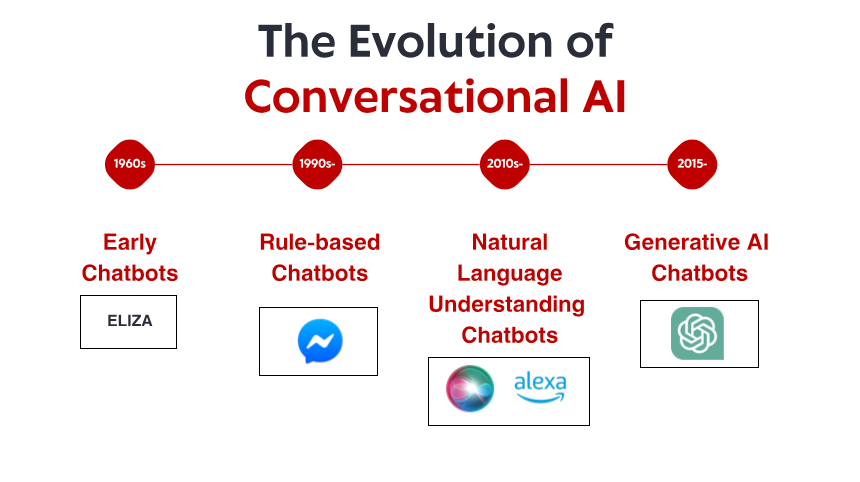
De bescheiden beginjaren: vroege op regels gebaseerde systemen
Het verhaal van conversationele AI begint in de jaren 60, lang voordat smartphones en spraakassistenten huishoudelijke apparaten werden. In een klein laboratorium aan het MIT creëerde computerwetenschapper Joseph Weizenbaum wat door velen wordt beschouwd als de eerste chatbot: ELIZA. Ontworpen om een Rogeriaanse psychotherapeut te simuleren, werkte ELIZA met eenvoudige patroonherkenning en substitutieregels. Wanneer een gebruiker "Ik voel me verdrietig" typte, kon ELIZA antwoorden met "Waarom voel je je verdrietig?" – wat de illusie van begrip creëerde door uitspraken te herformuleren als vragen.
Wat ELIZA opmerkelijk maakte, was niet de technische verfijning – naar huidige maatstaven was het programma ongelooflijk eenvoudig. Het was veeleer het diepgaande effect dat het op gebruikers had. Ondanks het feit dat ze wisten dat ze met een computerprogramma praatten zonder dat ze het echt begrepen, vormden veel mensen een emotionele band met ELIZA en deelden ze diep persoonlijke gedachten en gevoelens. Dit fenomeen, dat Weizenbaum zelf verontrustend vond, onthulde iets fundamenteels over de menselijke psychologie en onze bereidheid om zelfs de eenvoudigste conversationele interfaces te antropomorfiseren.
Gedurende de jaren 70 en 80 volgden op regels gebaseerde chatbots het ELIZA-model met stapsgewijze verbeteringen. Programma's zoals PARRY (die een paranoïde schizofreen simuleert) en RACTER (die een boek "The Policeman's Beard is Half Constructed" "auteur" was) bleven stevig binnen het op regels gebaseerde paradigma – gebruikmakend van vooraf gedefinieerde patronen, trefwoordmatching en templates.
Deze vroege systemen hadden ernstige beperkingen. Ze konden taal niet begrijpen, niet leren van interacties en zich niet aanpassen aan onverwachte input. Hun kennis was beperkt tot de regels die hun programmeurs expliciet hadden gedefinieerd. Wanneer gebruikers onvermijdelijk buiten deze grenzen traden, verbrijzelde de illusie van intelligentie snel, waardoor de onderliggende mechanische aard werd onthuld. Ondanks deze beperkingen legden deze baanbrekende systemen de basis waarop alle toekomstige conversationele AI zou voortbouwen.
Wat ELIZA opmerkelijk maakte, was niet de technische verfijning – naar huidige maatstaven was het programma ongelooflijk eenvoudig. Het was veeleer het diepgaande effect dat het op gebruikers had. Ondanks het feit dat ze wisten dat ze met een computerprogramma praatten zonder dat ze het echt begrepen, vormden veel mensen een emotionele band met ELIZA en deelden ze diep persoonlijke gedachten en gevoelens. Dit fenomeen, dat Weizenbaum zelf verontrustend vond, onthulde iets fundamenteels over de menselijke psychologie en onze bereidheid om zelfs de eenvoudigste conversationele interfaces te antropomorfiseren.
Gedurende de jaren 70 en 80 volgden op regels gebaseerde chatbots het ELIZA-model met stapsgewijze verbeteringen. Programma's zoals PARRY (die een paranoïde schizofreen simuleert) en RACTER (die een boek "The Policeman's Beard is Half Constructed" "auteur" was) bleven stevig binnen het op regels gebaseerde paradigma – gebruikmakend van vooraf gedefinieerde patronen, trefwoordmatching en templates.
Deze vroege systemen hadden ernstige beperkingen. Ze konden taal niet begrijpen, niet leren van interacties en zich niet aanpassen aan onverwachte input. Hun kennis was beperkt tot de regels die hun programmeurs expliciet hadden gedefinieerd. Wanneer gebruikers onvermijdelijk buiten deze grenzen traden, verbrijzelde de illusie van intelligentie snel, waardoor de onderliggende mechanische aard werd onthuld. Ondanks deze beperkingen legden deze baanbrekende systemen de basis waarop alle toekomstige conversationele AI zou voortbouwen.
De kennisrevolutie: expertsystemen en gestructureerde informatie
In de jaren 80 en begin jaren 90 ontstonden expertsystemen – AI-programma's die ontworpen waren om complexe problemen op te lossen door de besluitvormingsvaardigheden van menselijke experts in specifieke domeinen na te bootsen. Hoewel ze niet primair ontworpen waren voor conversatie, vormden deze systemen een belangrijke evolutionaire stap voor conversationele AI door een geavanceerdere kennisrepresentatie te introduceren.
Expertsystemen zoals MYCIN (die bacteriële infecties diagnosticeerden) en DENDRAL (die chemische verbindingen identificeerden) organiseerden informatie in gestructureerde kennisbanken en gebruikten inferentiesystemen om conclusies te trekken. Toegepast op conversationele interfaces, stelde deze aanpak chatbots in staat om verder te gaan dan eenvoudige patroonherkenning en te werken aan iets dat leek op redeneren – tenminste binnen beperkte domeinen.
Bedrijven begonnen met de implementatie van praktische toepassingen zoals geautomatiseerde klantenservicesystemen die deze technologie gebruikten. Deze systemen maakten doorgaans gebruik van beslissingsbomen en menugebaseerde interacties in plaats van vrije conversatie, maar ze waren vroege pogingen om interacties te automatiseren die voorheen menselijke tussenkomst vereisten.
De beperkingen bleven aanzienlijk. Deze systemen waren kwetsbaar en konden onverwachte invoer niet soepel verwerken. Ze vereisten enorme inspanningen van kennisingenieurs om informatie en regels handmatig te coderen. En misschien wel het belangrijkste: ze konden natuurlijke taal nog steeds niet echt begrijpen in al zijn complexiteit en ambiguïteit.
Desalniettemin werden in dit tijdperk belangrijke concepten ontwikkeld die later cruciaal zouden worden voor moderne conversationele AI: gestructureerde kennisrepresentatie, logische gevolgtrekking en domeinspecialisatie. De weg werd vrijgemaakt voor een paradigmaverschuiving, hoewel de technologie er nog niet helemaal klaar voor was.
Expertsystemen zoals MYCIN (die bacteriële infecties diagnosticeerden) en DENDRAL (die chemische verbindingen identificeerden) organiseerden informatie in gestructureerde kennisbanken en gebruikten inferentiesystemen om conclusies te trekken. Toegepast op conversationele interfaces, stelde deze aanpak chatbots in staat om verder te gaan dan eenvoudige patroonherkenning en te werken aan iets dat leek op redeneren – tenminste binnen beperkte domeinen.
Bedrijven begonnen met de implementatie van praktische toepassingen zoals geautomatiseerde klantenservicesystemen die deze technologie gebruikten. Deze systemen maakten doorgaans gebruik van beslissingsbomen en menugebaseerde interacties in plaats van vrije conversatie, maar ze waren vroege pogingen om interacties te automatiseren die voorheen menselijke tussenkomst vereisten.
De beperkingen bleven aanzienlijk. Deze systemen waren kwetsbaar en konden onverwachte invoer niet soepel verwerken. Ze vereisten enorme inspanningen van kennisingenieurs om informatie en regels handmatig te coderen. En misschien wel het belangrijkste: ze konden natuurlijke taal nog steeds niet echt begrijpen in al zijn complexiteit en ambiguïteit.
Desalniettemin werden in dit tijdperk belangrijke concepten ontwikkeld die later cruciaal zouden worden voor moderne conversationele AI: gestructureerde kennisrepresentatie, logische gevolgtrekking en domeinspecialisatie. De weg werd vrijgemaakt voor een paradigmaverschuiving, hoewel de technologie er nog niet helemaal klaar voor was.
Begrip van natuurlijke taal: de doorbraak in computationele taalkunde
Eind jaren negentig en begin jaren 2000 kwam er steeds meer aandacht voor natuurlijke taalverwerking (NLP) en computationele linguïstiek. In plaats van te proberen handmatig regels te programmeren voor elke mogelijke interactie, begonnen onderzoekers statistische methoden te ontwikkelen om computers te helpen de inherente patronen in menselijke taal te begrijpen.
Deze verschuiving werd mogelijk gemaakt door verschillende factoren: toenemende rekenkracht, betere algoritmen en, cruciaal, de beschikbaarheid van grote tekstcorpora die geanalyseerd konden worden om linguïstische patronen te identificeren. Systemen begonnen technieken te integreren zoals:
Part-of-speech tagging: Identificeren of woorden functioneerden als zelfstandige naamwoorden, werkwoorden, bijvoeglijke naamwoorden, enz.
Named entity recognition: Het detecteren en classificeren van eigennamen (personen, organisaties, locaties).
Sentimentanalyse: Het bepalen van de emotionele toon van een tekst.
Parsing: Het analyseren van zinsstructuur om grammaticale relaties tussen woorden te identificeren.
Een opmerkelijke doorbraak kwam met IBM's Watson, dat in 2011 menselijke kampioenen versloeg in de quiz Jeopardy! Hoewel het strikt genomen geen conversatiesysteem was, toonde Watson ongekende mogelijkheden om vragen in natuurlijke taal te begrijpen, enorme kennisbanken te doorzoeken en antwoorden te formuleren – mogelijkheden die essentieel zouden blijken voor de volgende generatie chatbots.
Commerciële toepassingen volgden al snel. Apple's Siri werd in 2011 gelanceerd en bracht conversatie-interfaces naar de mainstream consument. Hoewel beperkt door de huidige normen, vertegenwoordigde Siri een aanzienlijke vooruitgang in het toegankelijk maken van AI-assistenten voor alledaagse gebruikers. Microsoft's Cortana, Google's Assistant en Amazon's Alexa zouden volgen, elk met een verdere ontwikkeling van de state-of-the-art in conversatie-AI voor consumenten.
Ondanks deze vooruitgang worstelden systemen uit dit tijdperk nog steeds met context, logisch redeneren en het genereren van echt natuurlijk klinkende antwoorden. Ze waren geavanceerder dan hun op regels gebaseerde voorouders, maar bleven fundamenteel beperkt in hun begrip van taal en de wereld.
Deze verschuiving werd mogelijk gemaakt door verschillende factoren: toenemende rekenkracht, betere algoritmen en, cruciaal, de beschikbaarheid van grote tekstcorpora die geanalyseerd konden worden om linguïstische patronen te identificeren. Systemen begonnen technieken te integreren zoals:
Part-of-speech tagging: Identificeren of woorden functioneerden als zelfstandige naamwoorden, werkwoorden, bijvoeglijke naamwoorden, enz.
Named entity recognition: Het detecteren en classificeren van eigennamen (personen, organisaties, locaties).
Sentimentanalyse: Het bepalen van de emotionele toon van een tekst.
Parsing: Het analyseren van zinsstructuur om grammaticale relaties tussen woorden te identificeren.
Een opmerkelijke doorbraak kwam met IBM's Watson, dat in 2011 menselijke kampioenen versloeg in de quiz Jeopardy! Hoewel het strikt genomen geen conversatiesysteem was, toonde Watson ongekende mogelijkheden om vragen in natuurlijke taal te begrijpen, enorme kennisbanken te doorzoeken en antwoorden te formuleren – mogelijkheden die essentieel zouden blijken voor de volgende generatie chatbots.
Commerciële toepassingen volgden al snel. Apple's Siri werd in 2011 gelanceerd en bracht conversatie-interfaces naar de mainstream consument. Hoewel beperkt door de huidige normen, vertegenwoordigde Siri een aanzienlijke vooruitgang in het toegankelijk maken van AI-assistenten voor alledaagse gebruikers. Microsoft's Cortana, Google's Assistant en Amazon's Alexa zouden volgen, elk met een verdere ontwikkeling van de state-of-the-art in conversatie-AI voor consumenten.
Ondanks deze vooruitgang worstelden systemen uit dit tijdperk nog steeds met context, logisch redeneren en het genereren van echt natuurlijk klinkende antwoorden. Ze waren geavanceerder dan hun op regels gebaseerde voorouders, maar bleven fundamenteel beperkt in hun begrip van taal en de wereld.
Machine Learning en de datagestuurde aanpak
Halverwege de jaren 2010 vond er een nieuwe paradigmaverschuiving plaats in conversationele AI met de algemene acceptatie van machine learning-technieken. In plaats van te vertrouwen op handgemaakte regels of beperkte statistische modellen, begonnen ingenieurs systemen te bouwen die patronen rechtstreeks uit data konden leren – en wel heel veel.
In dit tijdperk ontstonden intentieclassificatie en entiteitsextractie als kerncomponenten van conversationele architectuur. Wanneer een gebruiker een verzoek deed, zou het systeem:
De algehele intentie classificeren (bijv. een vlucht boeken, het weer bekijken, muziek afspelen)
Relevante entiteiten extraheren (bijv. locaties, data, titels van nummers)
Deze koppelen aan specifieke acties of reacties
De lancering van het Messenger-platform door Facebook (nu Meta) in 2016 stelde ontwikkelaars in staat chatbots te creëren die miljoenen gebruikers konden bereiken, wat een golf van commerciële interesse teweegbracht. Veel bedrijven haastten zich om chatbots te implementeren, hoewel de resultaten wisselend waren. Vroege commerciële implementaties frustreerden gebruikers vaak vanwege een beperkt begrip en rigide conversatiestromen.
De technische architectuur van conversationele systemen evolueerde ook in deze periode. De typische aanpak omvatte een pijplijn van gespecialiseerde componenten:
Automatische spraakherkenning (voor spraakinterfaces)
Natuurlijk taalbegrip
Dialoogbeheer
Natuurlijke taalgeneratie
Tekst-naar-spraak (voor spraakinterfaces)
Elke component kon afzonderlijk worden geoptimaliseerd, wat incrementele verbeteringen mogelijk maakte. Deze pijplijnarchitecturen hadden echter soms last van foutpropagatie – fouten in de beginfase sijpelden door in het systeem.
Hoewel machine learning de mogelijkheden aanzienlijk verbeterde, hadden systemen nog steeds moeite met het behouden van context tijdens lange gesprekken, het begrijpen van impliciete informatie en het genereren van echt diverse en natuurlijke reacties. De volgende doorbraak zou een radicalere aanpak vereisen.
In dit tijdperk ontstonden intentieclassificatie en entiteitsextractie als kerncomponenten van conversationele architectuur. Wanneer een gebruiker een verzoek deed, zou het systeem:
De algehele intentie classificeren (bijv. een vlucht boeken, het weer bekijken, muziek afspelen)
Relevante entiteiten extraheren (bijv. locaties, data, titels van nummers)
Deze koppelen aan specifieke acties of reacties
De lancering van het Messenger-platform door Facebook (nu Meta) in 2016 stelde ontwikkelaars in staat chatbots te creëren die miljoenen gebruikers konden bereiken, wat een golf van commerciële interesse teweegbracht. Veel bedrijven haastten zich om chatbots te implementeren, hoewel de resultaten wisselend waren. Vroege commerciële implementaties frustreerden gebruikers vaak vanwege een beperkt begrip en rigide conversatiestromen.
De technische architectuur van conversationele systemen evolueerde ook in deze periode. De typische aanpak omvatte een pijplijn van gespecialiseerde componenten:
Automatische spraakherkenning (voor spraakinterfaces)
Natuurlijk taalbegrip
Dialoogbeheer
Natuurlijke taalgeneratie
Tekst-naar-spraak (voor spraakinterfaces)
Elke component kon afzonderlijk worden geoptimaliseerd, wat incrementele verbeteringen mogelijk maakte. Deze pijplijnarchitecturen hadden echter soms last van foutpropagatie – fouten in de beginfase sijpelden door in het systeem.
Hoewel machine learning de mogelijkheden aanzienlijk verbeterde, hadden systemen nog steeds moeite met het behouden van context tijdens lange gesprekken, het begrijpen van impliciete informatie en het genereren van echt diverse en natuurlijke reacties. De volgende doorbraak zou een radicalere aanpak vereisen.
De transformatorrevolutie: neurale taalmodellen
Het jaar 2017 markeerde een keerpunt in de geschiedenis van AI met de publicatie van "Attention Is All You Need", waarmee de Transformer-architectuur werd geïntroduceerd die een revolutie teweeg zou brengen in de natuurlijke taalverwerking. In tegenstelling tot eerdere benaderingen die tekst sequentieel verwerkten, konden Transformers een hele passage gelijktijdig analyseren, waardoor ze relaties tussen woorden beter konden vastleggen, ongeacht hun onderlinge afstand.
Deze innovatie maakte de ontwikkeling van steeds krachtigere taalmodellen mogelijk. In 2018 introduceerde Google BERT (Bidirectional Encoder Representations from Transformers), wat de prestaties bij diverse taken op het gebied van taalbegrip aanzienlijk verbeterde. In 2019 bracht OpenAI GPT-2 uit, met ongekende mogelijkheden voor het genereren van coherente, contextueel relevante tekst.
De meest dramatische sprong kwam in 2020 met GPT-3, dat opschaalde naar 175 miljard parameters (vergeleken met 1,5 miljard voor GPT-2). Deze enorme schaalvergroting, gecombineerd met architectonische verfijningen, leverde kwalitatief andere mogelijkheden op. GPT-3 kon opmerkelijk mensachtige tekst genereren, context begrijpen over duizenden woorden en zelfs taken uitvoeren waarvoor het niet expliciet was getraind.
Voor conversationele AI vertaalden deze ontwikkelingen zich in chatbots die:
Coherente gesprekken konden voeren gedurende meerdere gesprekken
Genuanceerde vragen konden begrijpen zonder expliciete training
Diverse, contextueel passende antwoorden konden genereren
Hun toon en stijl konden aanpassen aan de gebruiker
Omgaan met ambiguïteit en waar nodig verduidelijken
De release van ChatGPT eind 2022 bracht deze mogelijkheden naar de mainstream en trok binnen enkele dagen na de lancering meer dan een miljoen gebruikers aan. Plotseling had het grote publiek toegang tot conversationele AI die kwalitatief anders leek dan alles wat eraan voorafging – flexibeler, deskundiger en natuurlijker in de interacties.
Commerciële implementaties volgden snel, waarbij bedrijven grote taalmodellen integreerden in hun klantenserviceplatforms, tools voor contentcreatie en productiviteitsapplicaties. De snelle acceptatie weerspiegelde zowel de technologische sprong voorwaarts als de intuïtieve interface die deze modellen boden – conversatie is immers de meest natuurlijke manier voor mensen om te communiceren.
Deze innovatie maakte de ontwikkeling van steeds krachtigere taalmodellen mogelijk. In 2018 introduceerde Google BERT (Bidirectional Encoder Representations from Transformers), wat de prestaties bij diverse taken op het gebied van taalbegrip aanzienlijk verbeterde. In 2019 bracht OpenAI GPT-2 uit, met ongekende mogelijkheden voor het genereren van coherente, contextueel relevante tekst.
De meest dramatische sprong kwam in 2020 met GPT-3, dat opschaalde naar 175 miljard parameters (vergeleken met 1,5 miljard voor GPT-2). Deze enorme schaalvergroting, gecombineerd met architectonische verfijningen, leverde kwalitatief andere mogelijkheden op. GPT-3 kon opmerkelijk mensachtige tekst genereren, context begrijpen over duizenden woorden en zelfs taken uitvoeren waarvoor het niet expliciet was getraind.
Voor conversationele AI vertaalden deze ontwikkelingen zich in chatbots die:
Coherente gesprekken konden voeren gedurende meerdere gesprekken
Genuanceerde vragen konden begrijpen zonder expliciete training
Diverse, contextueel passende antwoorden konden genereren
Hun toon en stijl konden aanpassen aan de gebruiker
Omgaan met ambiguïteit en waar nodig verduidelijken
De release van ChatGPT eind 2022 bracht deze mogelijkheden naar de mainstream en trok binnen enkele dagen na de lancering meer dan een miljoen gebruikers aan. Plotseling had het grote publiek toegang tot conversationele AI die kwalitatief anders leek dan alles wat eraan voorafging – flexibeler, deskundiger en natuurlijker in de interacties.
Commerciële implementaties volgden snel, waarbij bedrijven grote taalmodellen integreerden in hun klantenserviceplatforms, tools voor contentcreatie en productiviteitsapplicaties. De snelle acceptatie weerspiegelde zowel de technologische sprong voorwaarts als de intuïtieve interface die deze modellen boden – conversatie is immers de meest natuurlijke manier voor mensen om te communiceren.
Testez l'IA sur VOTRE site web en 60 secondes
Voyez comment notre IA analyse instantanément votre site web et crée un chatbot personnalisé - sans inscription. Entrez simplement votre URL et regardez-la fonctionner !
Prêt en 60 secondes
Aucun codage requis
100% sécurisé
Multimodale mogelijkheden: verder dan alleen tekstgesprekken
Hoewel tekst de ontwikkeling van conversationele AI heeft gedomineerd, is er de laatste jaren een verschuiving gaande naar multimodale systemen die meerdere soorten media kunnen begrijpen en genereren. Deze evolutie weerspiegelt een fundamentele waarheid over menselijke communicatie: we gebruiken niet alleen woorden; we gebaren, tonen afbeeldingen, tekenen diagrammen en gebruiken onze omgeving om betekenis over te brengen.
Zichttaalmodellen zoals DALL-E, Midjourney en Stable Diffusion toonden aan dat ze afbeeldingen konden genereren op basis van tekstuele beschrijvingen, terwijl modellen zoals GPT-4 met visuele mogelijkheden afbeeldingen konden analyseren en intelligent konden bespreken. Dit opende nieuwe mogelijkheden voor conversationele interfaces:
Klantenservicebots die foto's van beschadigde producten kunnen analyseren
Winkelmedewerkers die artikelen kunnen identificeren aan de hand van afbeeldingen en vergelijkbare producten kunnen vinden
Educatieve tools die diagrammen en visuele concepten kunnen uitleggen
Toegankelijkheidsfuncties die afbeeldingen kunnen beschrijven voor gebruikers met een visuele beperking
Ook de spraakfunctionaliteit is enorm verbeterd. Vroege spraakinterfaces zoals IVR-systemen (Interactive Voice Response) waren notoir frustrerend en beperkt tot rigide commando's en menustructuren. Moderne spraakassistenten kunnen natuurlijke spraakpatronen begrijpen, rekening houden met verschillende accenten en spraakgebreken, en reageren met steeds natuurlijker klinkende, gesynthetiseerde stemmen.
De combinatie van deze mogelijkheden creëert een werkelijk multimodale conversationele AI die naadloos kan schakelen tussen verschillende communicatiemodi op basis van context en gebruikersbehoeften. Een gebruiker kan beginnen met een tekstuele vraag over het repareren van zijn printer, een foto van de foutmelding sturen, een diagram ontvangen met relevante knoppen en vervolgens overschakelen naar gesproken instructies terwijl zijn handen bezig zijn met de reparatie.
Deze multimodale aanpak vertegenwoordigt niet alleen een technische vooruitgang, maar ook een fundamentele verschuiving naar een meer natuurlijke interactie tussen mens en computer – waarbij gebruikers worden ontmoet in de communicatiemodus die het beste past bij hun huidige context en behoeften.
Zichttaalmodellen zoals DALL-E, Midjourney en Stable Diffusion toonden aan dat ze afbeeldingen konden genereren op basis van tekstuele beschrijvingen, terwijl modellen zoals GPT-4 met visuele mogelijkheden afbeeldingen konden analyseren en intelligent konden bespreken. Dit opende nieuwe mogelijkheden voor conversationele interfaces:
Klantenservicebots die foto's van beschadigde producten kunnen analyseren
Winkelmedewerkers die artikelen kunnen identificeren aan de hand van afbeeldingen en vergelijkbare producten kunnen vinden
Educatieve tools die diagrammen en visuele concepten kunnen uitleggen
Toegankelijkheidsfuncties die afbeeldingen kunnen beschrijven voor gebruikers met een visuele beperking
Ook de spraakfunctionaliteit is enorm verbeterd. Vroege spraakinterfaces zoals IVR-systemen (Interactive Voice Response) waren notoir frustrerend en beperkt tot rigide commando's en menustructuren. Moderne spraakassistenten kunnen natuurlijke spraakpatronen begrijpen, rekening houden met verschillende accenten en spraakgebreken, en reageren met steeds natuurlijker klinkende, gesynthetiseerde stemmen.
De combinatie van deze mogelijkheden creëert een werkelijk multimodale conversationele AI die naadloos kan schakelen tussen verschillende communicatiemodi op basis van context en gebruikersbehoeften. Een gebruiker kan beginnen met een tekstuele vraag over het repareren van zijn printer, een foto van de foutmelding sturen, een diagram ontvangen met relevante knoppen en vervolgens overschakelen naar gesproken instructies terwijl zijn handen bezig zijn met de reparatie.
Deze multimodale aanpak vertegenwoordigt niet alleen een technische vooruitgang, maar ook een fundamentele verschuiving naar een meer natuurlijke interactie tussen mens en computer – waarbij gebruikers worden ontmoet in de communicatiemodus die het beste past bij hun huidige context en behoeften.
Retrieval-Augmented Generation: AI baseren op feiten
Ondanks hun indrukwekkende mogelijkheden hebben grote taalmodellen inherente beperkingen. Ze kunnen informatie "hallucineren" en vol vertrouwen plausibel klinkende, maar onjuiste feiten presenteren. Hun kennis is beperkt tot wat er in hun trainingsdata stond, wat een kennisgrensdatum creëert. Bovendien missen ze de mogelijkheid om toegang te krijgen tot realtime informatie of gespecialiseerde databases, tenzij ze specifiek daarvoor zijn ontworpen.
Retrieval-Augmented Generation (RAG) kwam naar voren als een oplossing voor deze uitdagingen. In plaats van uitsluitend te vertrouwen op parameters die tijdens de training zijn geleerd, combineren RAG-systemen de generatieve mogelijkheden van taalmodellen met retrievalmechanismen die toegang hebben tot externe kennisbronnen.
De typische RAG-architectuur werkt als volgt:
Het systeem ontvangt een gebruikersvraag.
Het doorzoekt relevante kennisbanken naar informatie die relevant is voor de vraag.
Het stuurt zowel de vraag als de opgehaalde informatie naar het taalmodel.
Het model genereert een antwoord op basis van de opgehaalde feiten.
Deze aanpak biedt verschillende voordelen:
Nauwkeurigere, feitelijke antwoorden door de generatie te baseren op geverifieerde informatie.
De mogelijkheid om toegang te krijgen tot actuele informatie na de trainingslimiet van het model.
Gespecialiseerde kennis uit domeinspecifieke bronnen zoals bedrijfsdocumentatie.
Transparantie en attributie door het vermelden van de informatiebronnen.
Voor bedrijven die conversationele AI implementeren, is RAG bijzonder waardevol gebleken voor klantenservicetoepassingen. Een chatbot voor banken kan bijvoorbeeld toegang krijgen tot de meest recente beleidsdocumenten, rekeninginformatie en transactiegegevens om nauwkeurige, gepersonaliseerde antwoorden te geven die onmogelijk zouden zijn met een stand-alone taalmodel.
RAG-systemen evolueren verder en bieden verbeteringen op het gebied van de ophaalnauwkeurigheid, geavanceerdere methoden voor het integreren van opgehaalde informatie met gegenereerde tekst en betere mechanismen voor het evalueren van de betrouwbaarheid van verschillende informatiebronnen.
Retrieval-Augmented Generation (RAG) kwam naar voren als een oplossing voor deze uitdagingen. In plaats van uitsluitend te vertrouwen op parameters die tijdens de training zijn geleerd, combineren RAG-systemen de generatieve mogelijkheden van taalmodellen met retrievalmechanismen die toegang hebben tot externe kennisbronnen.
De typische RAG-architectuur werkt als volgt:
Het systeem ontvangt een gebruikersvraag.
Het doorzoekt relevante kennisbanken naar informatie die relevant is voor de vraag.
Het stuurt zowel de vraag als de opgehaalde informatie naar het taalmodel.
Het model genereert een antwoord op basis van de opgehaalde feiten.
Deze aanpak biedt verschillende voordelen:
Nauwkeurigere, feitelijke antwoorden door de generatie te baseren op geverifieerde informatie.
De mogelijkheid om toegang te krijgen tot actuele informatie na de trainingslimiet van het model.
Gespecialiseerde kennis uit domeinspecifieke bronnen zoals bedrijfsdocumentatie.
Transparantie en attributie door het vermelden van de informatiebronnen.
Voor bedrijven die conversationele AI implementeren, is RAG bijzonder waardevol gebleken voor klantenservicetoepassingen. Een chatbot voor banken kan bijvoorbeeld toegang krijgen tot de meest recente beleidsdocumenten, rekeninginformatie en transactiegegevens om nauwkeurige, gepersonaliseerde antwoorden te geven die onmogelijk zouden zijn met een stand-alone taalmodel.
RAG-systemen evolueren verder en bieden verbeteringen op het gebied van de ophaalnauwkeurigheid, geavanceerdere methoden voor het integreren van opgehaalde informatie met gegenereerde tekst en betere mechanismen voor het evalueren van de betrouwbaarheid van verschillende informatiebronnen.
Het samenwerkingsmodel tussen mens en AI: de juiste balans vinden
Naarmate de mogelijkheden van conversationele AI zich uitbreidden, is ook de relatie tussen mensen en AI-systemen geëvolueerd. Vroege chatbots werden duidelijk gepositioneerd als tools – beperkt in omvang en duidelijk niet-menselijk in hun interacties. Moderne systemen vervagen deze grenzen, wat nieuwe vragen oproept over hoe effectieve samenwerking tussen mens en AI kan worden ontworpen.
De meest succesvolle implementaties volgen vandaag de dag een collaboratief model waarbij:
De AI routinematige, repetitieve vragen afhandelt die geen menselijk oordeel vereisen.
Mensen zich richten op complexe gevallen die empathie, ethisch redeneren of creatieve probleemoplossing vereisen.
Het systeem kent zijn beperkingen en escaleert soepel naar menselijke agents wanneer dat nodig is.
De overgang tussen AI en menselijke ondersteuning verloopt naadloos voor de gebruiker.
Menselijke agents hebben volledige context over de gespreksgeschiedenis met de AI.
AI blijft leren van menselijke interventies en breidt zijn mogelijkheden geleidelijk uit.
Deze aanpak erkent dat conversationele AI er niet op gericht moet zijn om menselijke interactie volledig te vervangen, maar juist aan te vullen – door de grote hoeveelheid eenvoudige vragen af te handelen die de tijd van menselijke agents opslokken, terwijl ervoor wordt gezorgd dat complexe problemen de juiste menselijke expertise bereiken.
De implementatie van dit model verschilt per sector. In de gezondheidszorg kunnen AI-chatbots afspraken inplannen en basissymptoomscreening uitvoeren, terwijl ze ervoor zorgen dat medisch advies afkomstig is van gekwalificeerde professionals. In de juridische dienstverlening kan AI helpen bij het voorbereiden en onderzoeken van documenten, terwijl de interpretatie en strategie aan advocaten worden overgelaten. In de klantenservice kan AI veelvoorkomende problemen oplossen en complexe problemen doorsturen naar gespecialiseerde medewerkers.
Naarmate AI zich verder ontwikkelt, zal de grens tussen wat menselijke betrokkenheid vereist en wat geautomatiseerd kan worden, verschuiven, maar het fundamentele principe blijft: effectieve conversationele AI moet de menselijke capaciteiten versterken in plaats van ze simpelweg te vervangen.
De meest succesvolle implementaties volgen vandaag de dag een collaboratief model waarbij:
De AI routinematige, repetitieve vragen afhandelt die geen menselijk oordeel vereisen.
Mensen zich richten op complexe gevallen die empathie, ethisch redeneren of creatieve probleemoplossing vereisen.
Het systeem kent zijn beperkingen en escaleert soepel naar menselijke agents wanneer dat nodig is.
De overgang tussen AI en menselijke ondersteuning verloopt naadloos voor de gebruiker.
Menselijke agents hebben volledige context over de gespreksgeschiedenis met de AI.
AI blijft leren van menselijke interventies en breidt zijn mogelijkheden geleidelijk uit.
Deze aanpak erkent dat conversationele AI er niet op gericht moet zijn om menselijke interactie volledig te vervangen, maar juist aan te vullen – door de grote hoeveelheid eenvoudige vragen af te handelen die de tijd van menselijke agents opslokken, terwijl ervoor wordt gezorgd dat complexe problemen de juiste menselijke expertise bereiken.
De implementatie van dit model verschilt per sector. In de gezondheidszorg kunnen AI-chatbots afspraken inplannen en basissymptoomscreening uitvoeren, terwijl ze ervoor zorgen dat medisch advies afkomstig is van gekwalificeerde professionals. In de juridische dienstverlening kan AI helpen bij het voorbereiden en onderzoeken van documenten, terwijl de interpretatie en strategie aan advocaten worden overgelaten. In de klantenservice kan AI veelvoorkomende problemen oplossen en complexe problemen doorsturen naar gespecialiseerde medewerkers.
Naarmate AI zich verder ontwikkelt, zal de grens tussen wat menselijke betrokkenheid vereist en wat geautomatiseerd kan worden, verschuiven, maar het fundamentele principe blijft: effectieve conversationele AI moet de menselijke capaciteiten versterken in plaats van ze simpelweg te vervangen.
Het toekomstige landschap: waar conversationele AI naartoe gaat
Als we naar de horizon kijken, zien we verschillende opkomende trends die de toekomst van conversationele AI vormgeven. Deze ontwikkelingen beloven niet alleen incrementele verbeteringen, maar ook potentieel transformerende veranderingen in de manier waarop we met technologie omgaan.
Personalisatie op schaal: Toekomstige systemen zullen hun reacties steeds meer afstemmen op de directe context, maar ook op de communicatiestijl, voorkeuren, kennisniveau en relatiegeschiedenis van elke gebruiker. Deze personalisatie zal ervoor zorgen dat interacties natuurlijker en relevanter aanvoelen, hoewel het belangrijke vragen oproept over privacy en datagebruik.
Emotionele intelligentie: Terwijl huidige systemen basisgevoelens kunnen detecteren, zal toekomstige conversationele AI een geavanceerdere emotionele intelligentie ontwikkelen – subtiele emotionele toestanden herkennen, adequaat reageren op stress of frustratie en de toon en aanpak daarop aanpassen. Deze mogelijkheid zal met name waardevol zijn in klantenservice, gezondheidszorg en onderwijs.
Proactieve assistentie: In plaats van te wachten op expliciete vragen, zullen de volgende generatie conversationele systemen anticiperen op behoeften op basis van context, gebruikersgeschiedenis en omgevingssignalen. Een systeem kan bijvoorbeeld merken dat u meerdere vergaderingen plant in een onbekende stad en proactief vervoersopties of weersvoorspellingen aanbieden.
Naadloze multimodale integratie: Toekomstige systemen zullen verder gaan dan alleen het ondersteunen van verschillende modaliteiten en deze naadloos integreren. Een gesprek kan op natuurlijke wijze verlopen tussen tekst, spraak, afbeeldingen en interactieve elementen, waarbij de juiste modaliteit voor elk stukje informatie wordt gekozen zonder dat de gebruiker expliciet hoeft te kiezen.
Gespecialiseerde domeinexperts: Hoewel assistenten voor algemeen gebruik zullen blijven verbeteren, zullen we ook de opkomst zien van zeer gespecialiseerde conversationele AI met diepgaande expertise in specifieke domeinen – juridische assistenten die jurisprudentie en precedent begrijpen, medische systemen met uitgebreide kennis van geneesmiddelinteracties en behandelprotocollen, of financiële adviseurs die bedreven zijn in belastingwetgeving en beleggingsstrategieën.
Echt continu leren: Toekomstige systemen zullen verder gaan dan periodieke bijscholing en zullen continu leren van interacties, en in de loop der tijd behulpzamer en persoonlijker worden, met behoud van passende privacywaarborgen.
Ondanks deze interessante mogelijkheden blijven er uitdagingen bestaan. Privacyproblemen, het beperken van vooroordelen, passende transparantie en het vaststellen van het juiste niveau van menselijk toezicht zijn voortdurende kwesties die zowel de technologie als de regelgeving zullen bepalen. De meest succesvolle implementaties zullen die zijn die deze uitdagingen zorgvuldig aanpakken en tegelijkertijd echte waarde bieden aan gebruikers.
Het is duidelijk dat conversationele AI is geëvolueerd van een nichetechnologie naar een mainstream interfaceparadigma dat onze interacties met digitale systemen steeds meer zal bemiddelen. De evolutie van ELIZA's eenvoudige patroonherkenning naar de geavanceerde taalmodellen van vandaag de dag vertegenwoordigt een van de belangrijkste ontwikkelingen in de interactie tussen mens en computer – en de reis is nog lang niet voorbij.
Personalisatie op schaal: Toekomstige systemen zullen hun reacties steeds meer afstemmen op de directe context, maar ook op de communicatiestijl, voorkeuren, kennisniveau en relatiegeschiedenis van elke gebruiker. Deze personalisatie zal ervoor zorgen dat interacties natuurlijker en relevanter aanvoelen, hoewel het belangrijke vragen oproept over privacy en datagebruik.
Emotionele intelligentie: Terwijl huidige systemen basisgevoelens kunnen detecteren, zal toekomstige conversationele AI een geavanceerdere emotionele intelligentie ontwikkelen – subtiele emotionele toestanden herkennen, adequaat reageren op stress of frustratie en de toon en aanpak daarop aanpassen. Deze mogelijkheid zal met name waardevol zijn in klantenservice, gezondheidszorg en onderwijs.
Proactieve assistentie: In plaats van te wachten op expliciete vragen, zullen de volgende generatie conversationele systemen anticiperen op behoeften op basis van context, gebruikersgeschiedenis en omgevingssignalen. Een systeem kan bijvoorbeeld merken dat u meerdere vergaderingen plant in een onbekende stad en proactief vervoersopties of weersvoorspellingen aanbieden.
Naadloze multimodale integratie: Toekomstige systemen zullen verder gaan dan alleen het ondersteunen van verschillende modaliteiten en deze naadloos integreren. Een gesprek kan op natuurlijke wijze verlopen tussen tekst, spraak, afbeeldingen en interactieve elementen, waarbij de juiste modaliteit voor elk stukje informatie wordt gekozen zonder dat de gebruiker expliciet hoeft te kiezen.
Gespecialiseerde domeinexperts: Hoewel assistenten voor algemeen gebruik zullen blijven verbeteren, zullen we ook de opkomst zien van zeer gespecialiseerde conversationele AI met diepgaande expertise in specifieke domeinen – juridische assistenten die jurisprudentie en precedent begrijpen, medische systemen met uitgebreide kennis van geneesmiddelinteracties en behandelprotocollen, of financiële adviseurs die bedreven zijn in belastingwetgeving en beleggingsstrategieën.
Echt continu leren: Toekomstige systemen zullen verder gaan dan periodieke bijscholing en zullen continu leren van interacties, en in de loop der tijd behulpzamer en persoonlijker worden, met behoud van passende privacywaarborgen.
Ondanks deze interessante mogelijkheden blijven er uitdagingen bestaan. Privacyproblemen, het beperken van vooroordelen, passende transparantie en het vaststellen van het juiste niveau van menselijk toezicht zijn voortdurende kwesties die zowel de technologie als de regelgeving zullen bepalen. De meest succesvolle implementaties zullen die zijn die deze uitdagingen zorgvuldig aanpakken en tegelijkertijd echte waarde bieden aan gebruikers.
Het is duidelijk dat conversationele AI is geëvolueerd van een nichetechnologie naar een mainstream interfaceparadigma dat onze interacties met digitale systemen steeds meer zal bemiddelen. De evolutie van ELIZA's eenvoudige patroonherkenning naar de geavanceerde taalmodellen van vandaag de dag vertegenwoordigt een van de belangrijkste ontwikkelingen in de interactie tussen mens en computer – en de reis is nog lang niet voorbij.





